여러 데이터 합치기 (attach 명령)
동일한 데이터가 들어있는 sqlit3 db 파일이 있다.하나로 합치려고 하는데 어떻게 하면 되나? 1. 우선은 합칠 파일을 생성한다.# sqlite3 2016-08_ux_behavior_log.db2. .schema 명령으로 합칠 DB 테이블 생성한다.다른 콘솔에서# sqlite3 2016-08-01_ux_behavior_log.dbsqlite> .schemaCREATE TABLE log (user INT, time DATETIME, server TEXT, thread TEXT, checkoutId INT, page TEXT, action TEXT, vals TEXT,before TEXT, beforeType TEXT, changed TEXT, current TEXT, currentType TEXT, v..
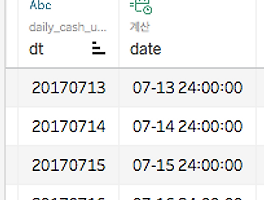
group by를 특정 값을 기준으로 누적하고 싶을 때... GROUP_CONCAT
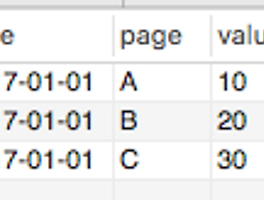
DB로 로그를 쌓고 있다. 사용자별로 어떤 페이지에 방문했는지 기록을 한다고 가정하자. 스키마는 단순하게 아래와 같이 컬럼으로 되어 있다고 치자. time, user, page 특정 사용자가 시간 순서대로 어떤 페이지에 방문을 했는지 보고 싶다. 이해를 돕기 위해 샘플 데이터를 해보면, raw데이터는 아래와 같이 행으로 되어 있다. time, user, page 07:33,A,login 07:34,A,mypage 07:40,A,changeForm 07:50,A,completeForm 07:55,A,logout 08:22,B,login 08:25,B,searchForm 08:26,B,readArticle 보고 싶은 데이터의 형태는 A, login-> mypage-> changeForm-> completeF..